 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak Out the Silverware -- Semantic Understanding of Stored Household Items
Dec 25, 2025``Bring me a plate.'' For domestic service robots, this simple command reveals a complex challenge: inferring where everyday items are stored, often out of sight in drawers, cabinets, or closets. Despite advances in vision and manipulation, robots still lack the commonsense reasoning needed to complete this task. We introduce the Stored Household Item Challenge, a benchmark task for evaluating service robots' cognitive capabilities: given a household scene and a queried item, predict its most likely storage location. Our benchmark includes two datasets: (1) a real-world evaluation set of 100 item-image pairs with human-annotated ground truth from participants' kitchens, and (2) a development set of 6,500 item-image pairs annotated with storage polygons over public kitchen images. These datasets support realistic modeling of household organization and enable comparative evaluation across agent architectures. To begin tackling this challenge, we introduce NOAM (Non-visible Object Allocation Model), a hybrid agent pipeline that combines structured scene understanding with large language model inference. NOAM converts visual input into natural language descriptions of spatial context and visible containers, then prompts a language model (e.g., GPT-4) to infer the most likely hidden storage location. This integrated vision-language agent exhibits emergent commonsense reasoning and is designed for modular deployment within broader robotic systems. We evaluate NOAM against baselines including random selection, vision-language pipelines (Grounding-DINO + SAM), leading multimodal models (e.g., Gemini, GPT-4o, Kosmos-2, LLaMA, Qwen), and human performance. NOAM significantly improves prediction accuracy and approaches human-level results, highlighting best practices for deploying cognitively capable agents in domestic environments.
General Dynamic Goal Recognition
May 14, 2025Understanding an agent's intent through its behavior is essential in human-robot interaction, interactive AI systems, and multi-agent collaborations. This task, known as Goal Recognition (GR), poses significant challenges in dynamic environments where goals are numerous and constantly evolving. Traditional GR methods, designed for a predefined set of goals, often struggle to adapt to these dynamic scenarios. To address this limitation, we introduce the General Dynamic GR problem - a broader definition of GR - aimed at enabling real-time GR systems and fostering further research in this area. Expanding on this foundation, this paper employs a model-free goal-conditioned RL approach to enable fast adaptation for GR across various changing tasks.
Gap the (Theory of) Mind: Sharing Beliefs About Teammates' Goals Boosts Collaboration Perception, Not Performance
May 06, 2025


In human-agent teams, openly sharing goals is often assumed to enhance planning, collaboration, and effectiveness. However, direct communication of these goals is not always feasible, requiring teammates to infer their partner's intentions through actions. Building on this, we investigate whether an AI agent's ability to share its inferred understanding of a human teammate's goals can improve task performance and perceived collaboration. Through an experiment comparing three conditions-no recognition (NR), viable goals (VG), and viable goals on-demand (VGod) - we find that while goal-sharing information did not yield significant improvements in task performance or overall satisfaction scores, thematic analysis suggests that it supported strategic adaptations and subjective perceptions of collaboration. Cognitive load assessments revealed no additional burden across conditions, highlighting the challenge of balancing informativeness and simplicity in human-agent interactions. These findings highlight the nuanced trade-off of goal-sharing: while it fosters trust and enhances perceived collaboration, it can occasionally hinder objective performance gains.
GRAML: Dynamic Goal Recognition As Metric Learning
May 06, 2025Goal Recognition (GR) is the problem of recognizing an agent's objectives based on observed actions. Recent data-driven approaches for GR alleviate the need for costly, manually crafted domain models. However, these approaches can only reason about a pre-defined set of goals, and time-consuming training is needed for new emerging goals. To keep this model-learning automated while enabling quick adaptation to new goals, this paper introduces GRAML: Goal Recognition As Metric Learning. GRAML uses a Siamese network to treat GR as a deep metric learning task, employing an RNN that learns a metric over an embedding space, where the embeddings for observation traces leading to different goals are distant, and embeddings of traces leading to the same goals are close. This metric is especially useful when adapting to new goals, even if given just one example observation trace per goal. Evaluated on a versatile set of environments, GRAML shows speed, flexibility, and runtime improvements over the state-of-the-art GR while maintaining accurate recognition.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Birds of a Different Feather Flock Together: Exploring Opportunities and Challenges in Animal-Human-Machine Teaming
Apr 17, 2025Animal-Human-Machine (AHM) teams are a type of hybrid intelligence system wherein interactions between a human, AI-enabled machine, and animal members can result in unique capabilities greater than the sum of their parts. This paper calls for a systematic approach to studying the design of AHM team structures to optimize performance and overcome limitations in various applied settings. We consider the challenges and opportunities in investigating the synergistic potential of AHM team members by introducing a set of dimensions of AHM team functioning to effectively utilize each member's strengths while compensating for individual weaknesses. Using three representative examples of such teams -- security screening, search-and-rescue, and guide dogs -- the paper illustrates how AHM teams can tackle complex tasks. We conclude with open research directions that this multidimensional approach presents for studying hybrid human-AI systems beyond AHM teams.
All You Need is Sally-Anne: ToM in AI Strongly Supported After Surpassing Tests for 3-Year-Olds
Mar 31, 2025Theory of Mind (ToM) is a hallmark of human cognition, allowing individuals to reason about others' beliefs and intentions. Engineers behind recent advances in Artificial Intelligence (AI) have claimed to demonstrate comparable capabilities. This paper presents a model that surpasses traditional ToM tests designed for 3-year-old children, providing strong support for the presence of ToM in AI systems.
Goal Recognition using Actor-Critic Optimization
Dec 31, 2024Goal Recognition aims to infer an agent's goal from a sequence of observations. Existing approaches often rely on manually engineered domains and discrete representations. Deep Recognition using Actor-Critic Optimization (DRACO) is a novel approach based on deep reinforcement learning that overcomes these limitations by providing two key contributions. First, it is the first goal recognition algorithm that learns a set of policy networks from unstructured data and uses them for inference. Second, DRACO introduces new metrics for assessing goal hypotheses through continuous policy representations. DRACO achieves state-of-the-art performance for goal recognition in discrete settings while not using the structured inputs used by existing approaches. Moreover, it outperforms these approaches in more challenging, continuous settings at substantially reduced costs in both computing and memory. Together, these results showcase the robustness of the new algorithm, bridging traditional goal recognition and deep reinforcement learning.
To What Extent Does the Perceived Obesity Level of Humanoid Robots Affect People's Trust in Them?
Nov 09, 2024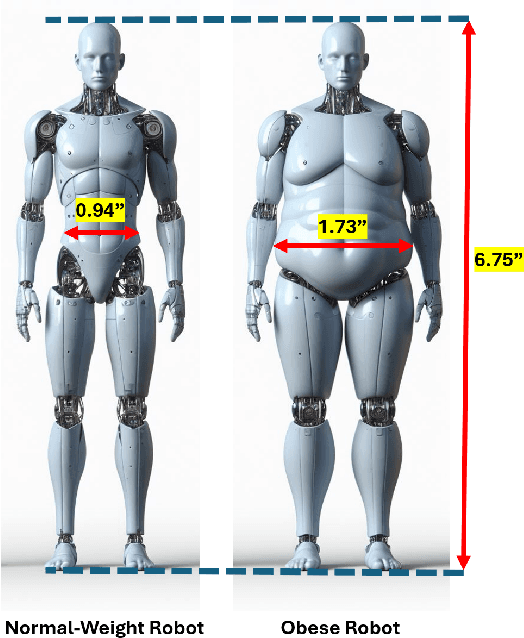
Despite obesity being widely discussed in the social sciences, the effect of a robot's perceived obesity level on trust is not covered by the field of HRI. While in research regarding humans, Body Mass Index (BMI) is commonly used as an indicator of obesity, this scale is completely irrelevant in the context of robots, so it is challenging to operationalize the perceived obesity level of robots; indeed, while the effect of robot's size (or height) on people's trust in it was addressed in previous HRI papers, the perceived obesity level factor has not been addressed. This work examines to what extent the perceived obesity level of humanoid robots affects people's trust in them. To test this hypothesis, we conducted a within-subjects study where, using an online pre-validated questionnaire, the subjects were asked questions while being presented with two pictures of humanoids, one with a regular obesity level and the other with a high obesity level. The results show that humanoid robots with lower perceived obesity levels are significantly more likely to be trusted.
Shared Control with Black Box Agents using Oracle Queries
Oct 25, 2024



Shared control problems involve a robot learning to collaborate with a human. When learning a shared control policy, short communication between the agents can often significantly reduce running times and improve the system's accuracy. We extend the shared control problem to include the ability to directly query a cooperating agent. We consider two types of potential responses to a query, namely oracles: one that can provide the learner with the best action they should take, even when that action might be myopically wrong, and one with a bounded knowledge limited to its part of the system. Given this additional information channel, this work further presents three heuristics for choosing when to query: reinforcement learning-based, utility-based, and entropy-based. These heuristics aim to reduce a system's overall learning cost. Empirical results on two environments show the benefits of querying to learn a better control policy and the tradeoffs between the proposed heuristics.